이 예시를 보면 이미지가 600px을 넘지 않을 것을 보증한다. 그리고 600px보다 작은 경우에는 알아서 크기를 줄인다.
max()
max는 반응형 요소에서 최소값의 경계를 지정한다.
max()의 경우 min()의 반대다.
max()로 문맥상 여백 주기
Web Content Accessibility Guidelines (WCAG) Success Criterion 1.4.10에 따르면 사이트를 최대 400%까지 확대할 수 있어야한다. 이때 px과 rem은 표준에 맞지 않는 단위이다.
만약에 1280px사이즈의 데스크톱에 400% 줌을 준다면 뷰포트 너비가 320px로 줄어든다. 이때 모바일에서 이를 한다면, 방향은 가로로 계속 유지된다. 이러한 뷰포트의 축소는 읽기와 상호작용 영역이 감소했음을 의미한다. 더하여 휴대폰에서는 적합한 크기가 확대된 창에서는 훨씬 커보일 수 있다.
이때 쓸 수 있는 것이 max()이다. 원문의 저자는 작은 여백에는 rem단위를 선호한다. 하지만 영역 간의 큰 여백을 줘야하는 경우에는 아래와 같은 코드를 사용한다. 이렇게 하면 뷰포트에 따라 조정이 된다.
HomeLink.propTypes = { /** 제목 요소를 설정합니다. */ as: oneOf(['h1','h2','h3','h4','h5','h6']), /** 언어를 지정할 수 있습니다. (스크린 리더 음성 변경 됨) */ lang: oneOf(['en', 'ko']), /** 클래스 이름을 추가할 수 있습니다. */ className: string, }
exportdefault HomeLink;
여기서 기본값인 defaultProps를 작성하고 props에 대한 타입을 지정하기 위해 propTypes를 설정한다. 타입스크립트의 경우 이부분은 생략할 수 있다. 만든 컴포넌트는 다시 내보낸다.
같은 경로에 HomeLink.stories.js를 생성하고 스토리 파일을 작성한다. export default안에 있는 블럭은 각각 다음과 같다.
title : 스토리 파일 내에서 경로 설정
componenet : 해당 컴포넌트에 대한 설명
table : 스토리북 내에서 props의 표시 유무를 설정하는 값. 기본적으론 false이며 이 값이 true로 변경하는 경우 스토리북 내에서 해당 props가 보이지 않게 된다.
props값에 따라 컴포넌트가 어떻게 변화하는지 보고 싶은 경우에는 템플릿을 작성하여 이를 보여줄 수 있다. Template를 선언하고 여기에 객체를 바인딩하여 내가 전달하고자 하는 props를 매개변수로 전달한다. 이 때 storyName을 통해 스토리북 내에서 표시될 이름을 설정할 수 있다.
noreferrer는 <a>, <area>, <form>의 rel 속성에 쓰는 속성 값이다. 타겟 브라우저로 이동할 때 원 브라우저에 대한 정보(Referer)를 제공하지 않는다. 레퍼러를 제공하지 않기 때문에 새 탭으로 인한 보안 문제가 해결된다. 이런 면에서는 noopener가 쓰인 것과 같은 효과를 볼 수 있다.
noopener란 a, area, form태그의 rel속성에 들어가는 속성 값이다. 이 값은 새로운 창이 열려있을 때, 기존에 브라우징 되어있는 요소에 접근할 수 없도록 한다.
A브라우저에서 링크를 타고 B브라우저를 새탭에서 열었을 경우 Window.opener라는 객체가 생기는데, 이걸 통해 B브라우저가 A브라우저를 악의적으로 동작하게 만들 수 있기 때문에 noopener는 이 객체를 생성하지 않고 널값을 반환한다.
이 값은 특히 신뢰할 수 없는 사이트에 들어갈 때 유용하다. 이 값을 사용하면 Window.opener를 통해서 현재 브라우저에 접근할 수 있는 통로를 차단한다. (이 값을 사용한다는 기본 전제는 RefererHTTP 헤더를 사용한다는 것이다. 리퍼러는 사용자가 어디에서 새 브라우저로 왔는지 url에 보여준다. 이 정보가 명확히 있기 때문에 Window.opener에서 조작할 수 있는건데, noreferrer를 사용한다면 애초에 어디서부터 왔는지 보이지 않기 때문에 noopener를 사용할 이유가 없어진다.)
noopener를 사용할 경우 target속성에 기존 속성값이 아닌 임의의 값을 넣으면 _blank처럼 여겨져서 계속 새로운 창을 띄운다.(원래는 프레임 내임으로 탭이 하나 생성되고 링크를 여러번 타도 그 창을 삭제하지 않는 한 새로운 탭이 생성되지 않는다.)
가사에 사용된 모든 단어들이 담긴 배열 words에서 queries에 해당되는 단어가 몇 개가 있는지 반환하는 문제이다. queries에는 와일드 카드 ?가 하나 이상 존재하며, 이 와일드 카드는 문자의 앞부분을 차지하거나 뒷부분만을 차지한다(fr?do와 같은 형식이 없다.).
문제 링크
문제풀이
trie 자료구조를 이용하여 문제를 풀 수 있다. 이번에는 다른 분의 핵심 아이디어를 듣고 코드로 구현하였다. 코드는 아래와 같다.
defadd(self, value:str): node = self.root for c in value: # add dictionary for wildcard iflen(value) notin node.len_dict: node.len_dict[len(value)] = 0 node.len_dict[len(value)] += 1 if c notin node.child: # There is no child new_node = Node(c) node.child[c] = new_node node = new_node else: node = node.child[c] node.child['*'] = None
defsearch(self, queri): node = self.root for c in queri: if c == '?': return node.len_dict[len(queri)] iflen(queri) in node.len_dict else0 if c in node.child: node = node.child[c] else: return0
# if root.value is not None: # print(root.value, end = " ")
# if '*' in root.child: # print('*') # continue
# for node in root.child.values(): # queue.append(node) reversed_words = [word[::-1] for word in words]
trie = Trie() for word in words: trie.add(word)
reversed_trie = Trie() for word in reversed_words: reversed_trie.add(word)
answer = []
for queri in queries: if queri[0] == '?': answer.append(reversed_trie.search(queri[::-1])) else: answer.append(trie.search(queri)) return answer
일단 Trie에 대해서 알아야 하는데 이에 대한 링크를 첨부해 두었으니 참고하면 좋을 것 같다. 이에 대해 안다고 가정하고 설명을 진행한다.
이 문제에서 제한 시간내에 문제를 풀기 위한 핵심 요소는 와일드 카드의 사용이다. 문자 사이에 와일드 카드가 올 일은 없기 때문에 만약 접미사가 와일드 카드이면 더 이상 Trie를 탐색하지 않도록 해야 문제가 풀린다.
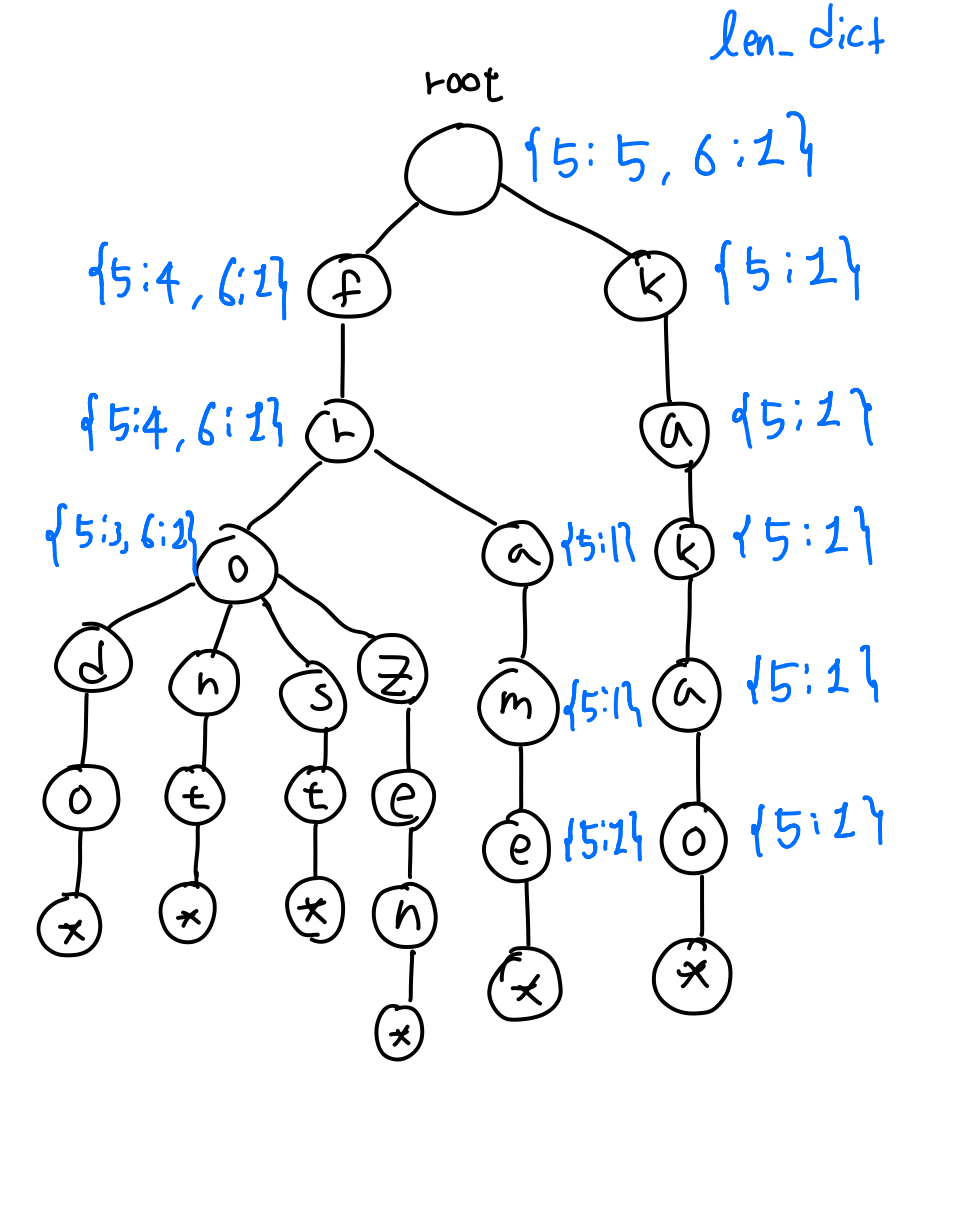
이를 풀기 위해 len_dict를 생성하였다. len_dict는 해당 노드에서 뻗어나가는 단어들을 길이에 따라 몇 개의 단어가 있는지 알려주는 딕셔너리이다. 문제 테스트 케이스에 대해 len_dict를 그려보자면 다음과 같다.
Trie와 len_dict
그림을 보면 root에 5글자를 가진 단어 5개 6글자를 가진 단어 1개를 표시해두고 아래로 뻗어 나가면서 각자의 위치에 자신의 하위 위치에 있는 단어들의 개수를 길이에 따라 저장해둔 것을 볼 수 있다. 이런식으로 했을때 만약 fro??와 같은 쿼리가 들어오면 o까지만 순회를 하고 5를 key값으로 하는 value 3을 리턴해주면 된다.
이렇게 하면 해결하지 못하는 케이스가 여전히 있는데 바로 와일드 카드가 앞쪽에 붙는 경우다. 이렇게 하면 모든 단어를 순회해봐야 알 수 있게 되기 때문에 역시나 효율성에서 애를 먹는다. 이를 해결하는 방법은 간단한다. 단어를 거꾸로 하여 새로운 Trie를 만들고 쿼리도 역으로 하여 search를 진행하면 된다.
시간복잡도를 계산하자면, words의 길이를 n, 개수를 m이라 하면 trie를 생성하는데에 \(O(nm)\)이 든다. 이를 만들고 쿼리를 진행하므로 queries의 길이를 q라하고 개수를 p라하면, \(O(pq)\)만큼 소요된다. 따라서 최종 시간복잡도는 \(O(nm) + O(pq)\)이다.
너무 시간복잡도가 어마어마하게 느껴질 수도 있지만, 와일드카드와 단어간의 중첩이 있어 실질적인 시간은 좀 더 짧다고 생각한다.