가사 검색
문제정의
가사에 사용된 모든 단어들이 담긴 배열 words에서 queries에 해당되는 단어가 몇 개가 있는지 반환하는 문제이다. queries에는 와일드 카드 ?가 하나 이상 존재하며, 이 와일드 카드는 문자의 앞부분을 차지하거나 뒷부분만을 차지한다(fr?do와 같은 형식이 없다.).
문제 링크
문제풀이
trie 자료구조를 이용하여 문제를 풀 수 있다. 이번에는 다른 분의 핵심 아이디어를 듣고 코드로 구현하였다. 코드는 아래와 같다.
1 | def solution(words, queries): |
일단 Trie에 대해서 알아야 하는데 이에 대한 링크를 첨부해 두었으니 참고하면 좋을 것 같다. 이에 대해 안다고 가정하고 설명을 진행한다.
이 문제에서 제한 시간내에 문제를 풀기 위한 핵심 요소는 와일드 카드의 사용이다. 문자 사이에 와일드 카드가 올 일은 없기 때문에 만약 접미사가 와일드 카드이면 더 이상 Trie를 탐색하지 않도록 해야 문제가 풀린다.
이를 풀기 위해 len_dict를 생성하였다. len_dict는 해당 노드에서 뻗어나가는 단어들을 길이에 따라 몇 개의 단어가 있는지 알려주는 딕셔너리이다. 문제 테스트 케이스에 대해 len_dict를 그려보자면 다음과 같다.
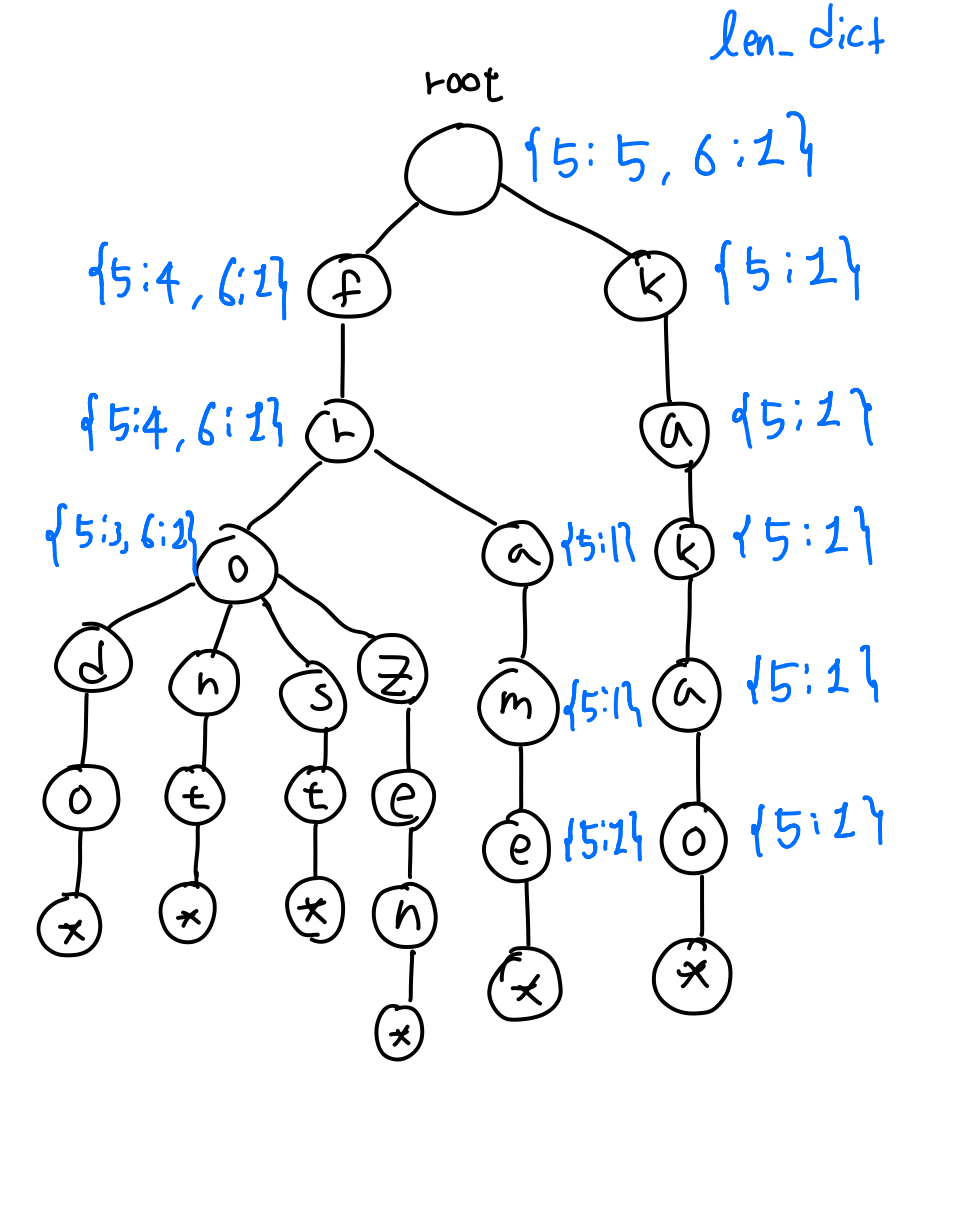
그림을 보면 root에 5글자를 가진 단어 5개 6글자를 가진 단어 1개를 표시해두고 아래로 뻗어 나가면서 각자의 위치에 자신의 하위 위치에 있는 단어들의 개수를 길이에 따라 저장해둔 것을 볼 수 있다. 이런식으로 했을때 만약 fro??와 같은 쿼리가 들어오면 o까지만 순회를 하고 5를 key값으로 하는 value 3을 리턴해주면 된다.
이렇게 하면 해결하지 못하는 케이스가 여전히 있는데 바로 와일드 카드가 앞쪽에 붙는 경우다. 이렇게 하면 모든 단어를 순회해봐야 알 수 있게 되기 때문에 역시나 효율성에서 애를 먹는다. 이를 해결하는 방법은 간단한다. 단어를 거꾸로 하여 새로운 Trie를 만들고 쿼리도 역으로 하여 search를 진행하면 된다.
시간복잡도를 계산하자면, words의 길이를 n, 개수를 m이라 하면 trie를 생성하는데에 \(O(nm)\)이 든다. 이를 만들고 쿼리를 진행하므로 queries의 길이를 q라하고 개수를 p라하면, \(O(pq)\)만큼 소요된다. 따라서 최종 시간복잡도는 \(O(nm) + O(pq)\)이다.
너무 시간복잡도가 어마어마하게 느껴질 수도 있지만, 와일드카드와 단어간의 중첩이 있어 실질적인 시간은 좀 더 짧다고 생각한다.
테스트
