평범한 배낭
문제정의
0-1 knapsack 문제이다.
문제풀이
이번에는 내 코드와 강사님이 최적화를 거친 코드를 단계로 보며 DP에 대해 정리하려고 한다. 일단 필자의 코드는 아래와 같다.
1 | N, K = map(int, input().split(" ")) |
재귀를 이용한 구현이다. 가용치를 W라하고, n을 넣을 물건의 고유번호라고 생각하면, 이 둘이 0일 때 반환하는 값은 0이다.
계산했던 값을 저장하기 위해 max_dict 딕셔너리를 이용하였다. 여기에 들어가는 키 값은 물건의 고유번호와 가용치가 묶인 튜플이다. 값으로는 최대가치를 반환한다.
이 값이 만약에 존재한다면 계산 해뒀던 값이므로 이 값을 반환한다. 그렇지 않은 경우 값을 새로 계산하여야 한다. 만약 가용치안에 현재 물건이 들어갈 수 있다면, 들어간 경우와 그렇지 않은 경우를 모두 고려하여 값을 계산한다.
가용치안에 물건이 들어갈 수 없다면 없는 경우만 고려하면 된다. 이 때 계산한 값을 딕셔너리에 저장하는 것을 잊지말자!
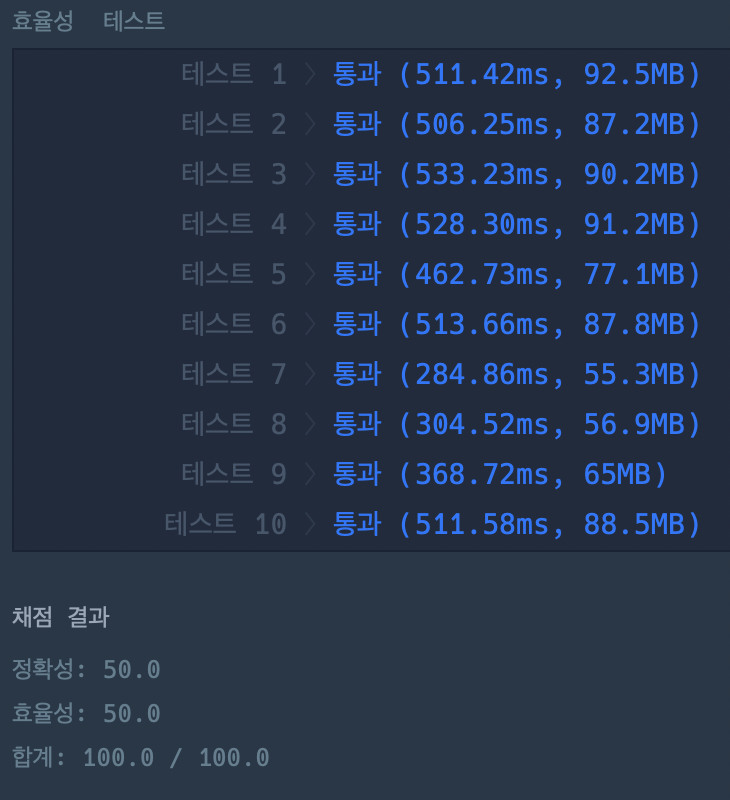
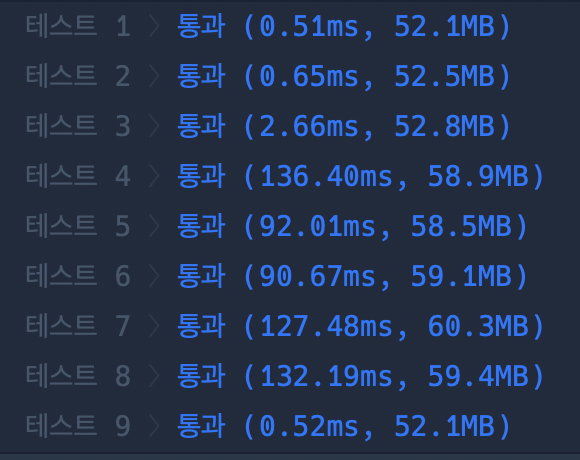
백준에 결과를 돌려보면 다음과 같다.

이제 여기서 최적화를 한 단계씩 해나갈 수 있다. 기존의 Top-down방식을 Bottom-up으로 구성하면 코드는 다음과 같이 변경할 수 있다.
1 | N, K = map(int, input.split()) |
dp라는 2차원 리스트를 만들어서 i번째 물건을 가중치 W에 따라 넣는 경우와 넣지 않는 경우, 넣지 못하는 경우를 전부 기록한다.

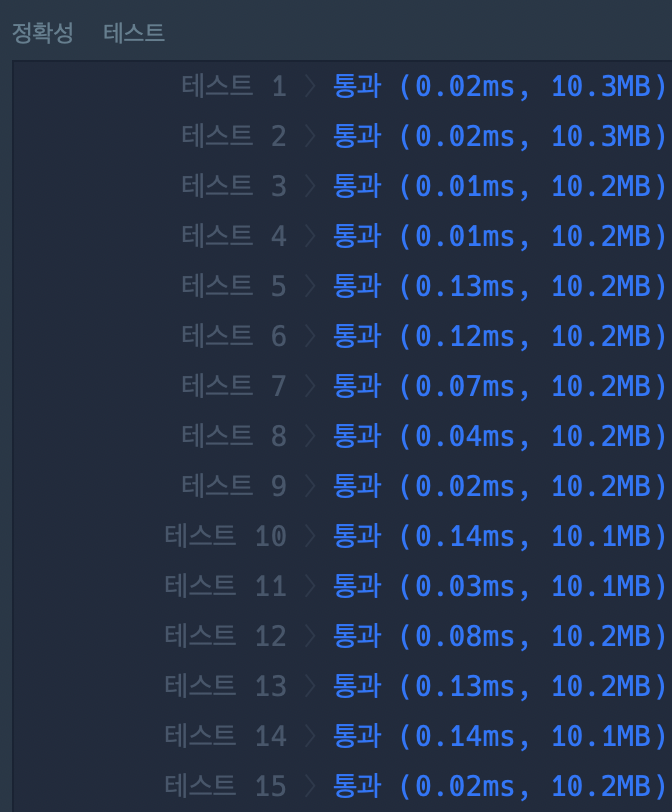
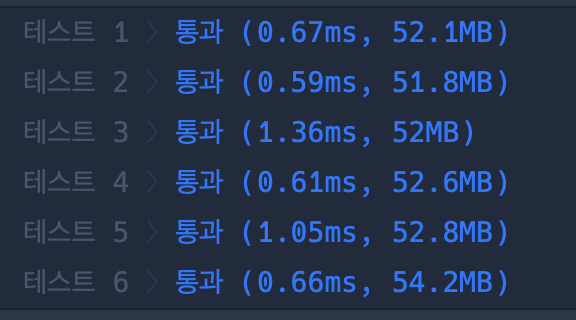
위와 비교하여 메모리도 늘고 시간도 늘었다. 실은 이건 재귀에 비하면 느릴 수 있는게 애초에 2차원 배열의 모든 요소를 사용하지 않기 때문에 메모리 낭비가 있기 때문이다. 그리고 표의 모든 요소를 채우기 때문에 시간도 그만큼 오래 걸린다. 하지만 재귀같은 경우 998번이 넘는 호출을 할수가 없기 떄문에 데이터 값이 큰 경우 재귀는 사용하기 어렵기 때문에 이걸 알아놔야 한다.
여기서 보이는 개선 방안은 크게 두가지 이다.
- 공간의 낭비
- 표의 모든 요소를 계산할 필요가 없는 것
이 두가지를 최적화 시켜나가려고 한다. 일단 공간적인 면에서 최적화를 시켜보자. 코드를 자세히 보면 점화식을 사용하는 부분에서 i-1번째 줄만 사용하는 것을 볼 수 있다. 그럼 그 이전의 행은 더 이상 쓸 일이 없으므로 이 부분에 대해서 최적화를 하면 다음과 같은 코드로 변경할 수 있다.
1 |
|
i값에 따라 번갈아 가면서 값을 쓸 수 있도록 하였다.

연산 횟수는 다르지 않기 때문에 걸리는 시간은 그대로지만, 메모리 사용량이 크게 준 것을 확인하였다.
여기서 이제 2번에 대한 최적화를 추가로 할 수 있다. 연산량을 줄이는 것인데, 재귀로 코드를 짰을 때 호출되는 w 값을 계산하여 이를 저장하고 for문에서 이 값들에 대한 계산만 하면 최적화를 할 수 있다.
코드는 아래와 같다.
1 | N, K = map(int, input().split()) |
첫번째 for문을 주목하자. 우리는 이미 점화식을 통해 계산해야 하는 w값을 알 수 있다. 그래서 초기에 최종 가용치만을 넣어두고 여기에서 두 경우(선택하는 경우와 하지 않는 경우)로 나누어서 계산에 쓰이는 w값만 need_calc에 넣는다.

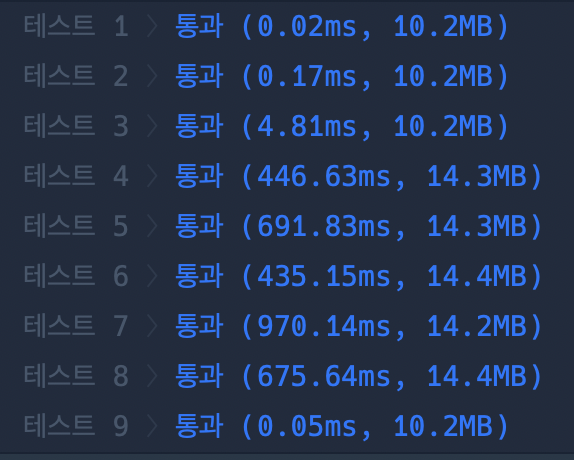
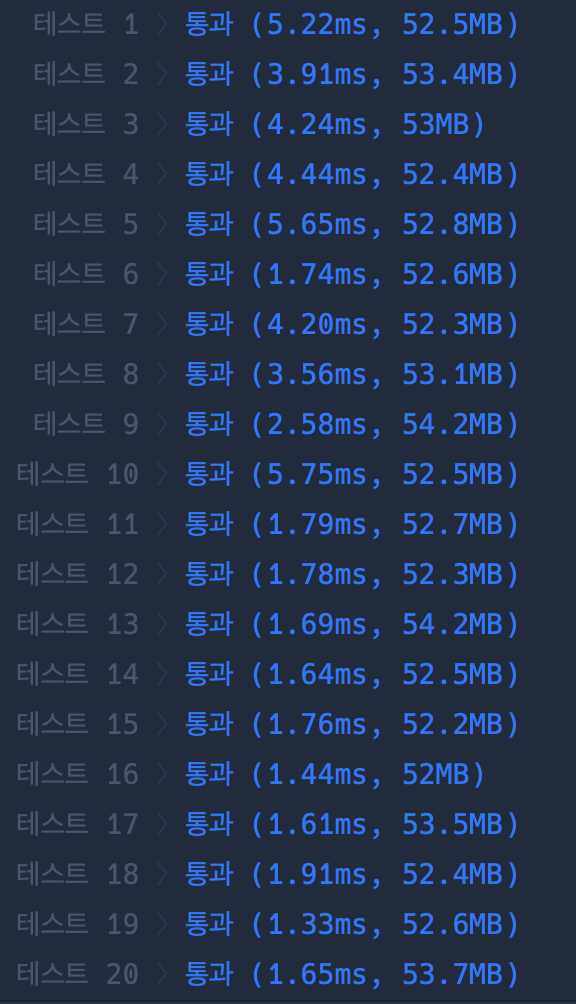
오버헤드가 없기 때문에 시간이 재귀보다 단축한 것을 볼 수 있다. 이렇게 최적화 과정에 대해 공부하였는데, 공부를 많이 해야겠다는 생각이 든다. 기죽지 말고 꾸준히 공부해야겠다. ✍️