전화번호 목록
문제정의
전화번호 목록이 주어질 때 어떤 번호가 다른 번호의 접두사인지 파악하는 문제이다.
문제풀이
전체 코드는 다음과 같다. 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31package level2;
import java.util.ArrayList;
public class PhoneBook {
//프로그래머스 문제풀이 level2 전화번호 목록
public static void main(String[] args) {
String[] phone_book = {"119", "97674223", "1195524421"};
boolean answer = true;
ArrayList<ArrayList<String>> list = new ArrayList<ArrayList<String>>(10);
for (int i = 0; i < 10; i++)
list.add(new ArrayList<String>());
for(String s : phone_book)
{
int idx = Integer.parseInt(s.substring(0,1));
for(int i = 0; i < list.get(idx).size(); i++)
{
String comp = list.get(idx).get(i);
if(s.indexOf(comp) == 0 || comp.indexOf(s) == 0)
{
answer = false;
break;
}
}
list.get(idx).add(s);
}
System.out.println(answer);
}
}
실은 이것도 모두 같은 숫자로 시작하면서 서로 접두사가 아닌 케이스인 경우 결국 \(O(n^2)\)이다.
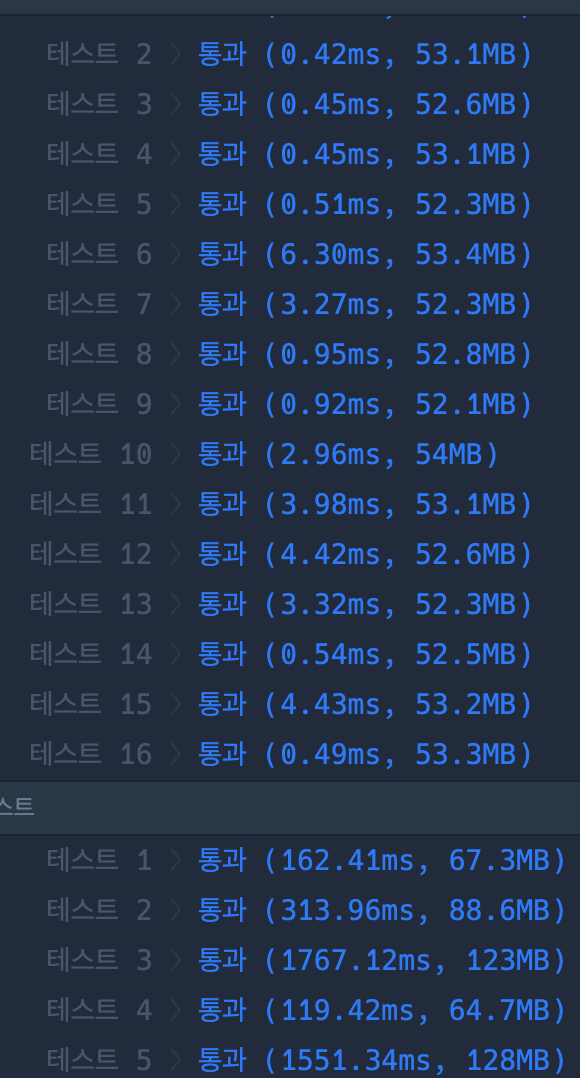
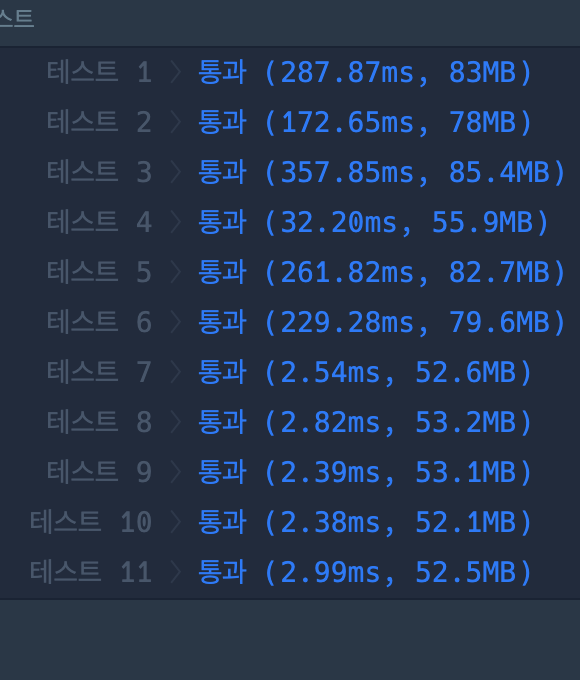
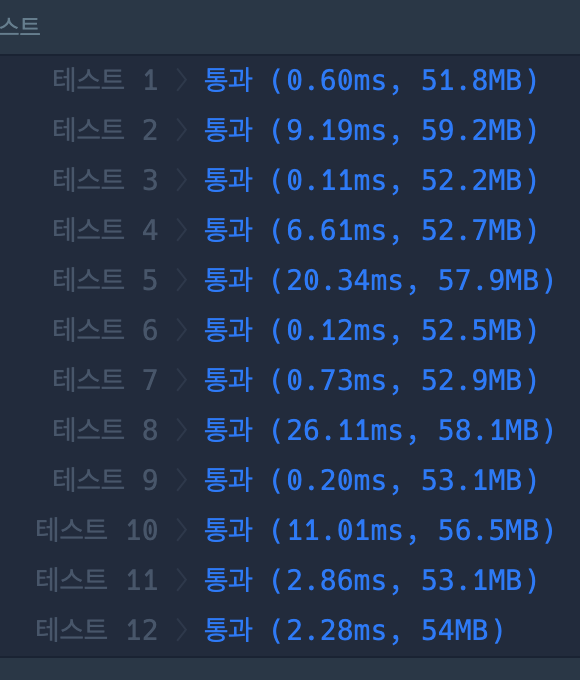
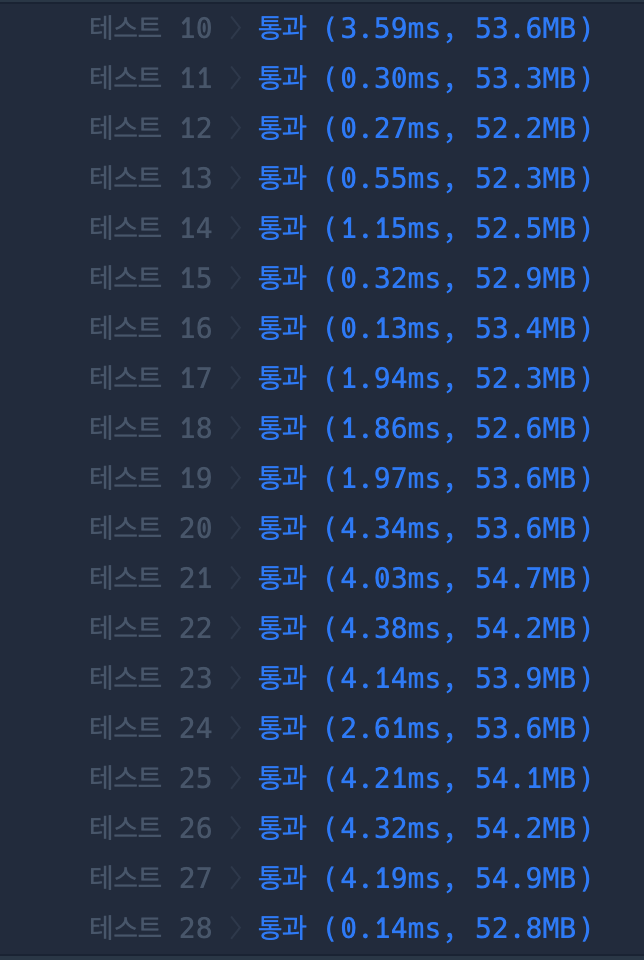
테스트
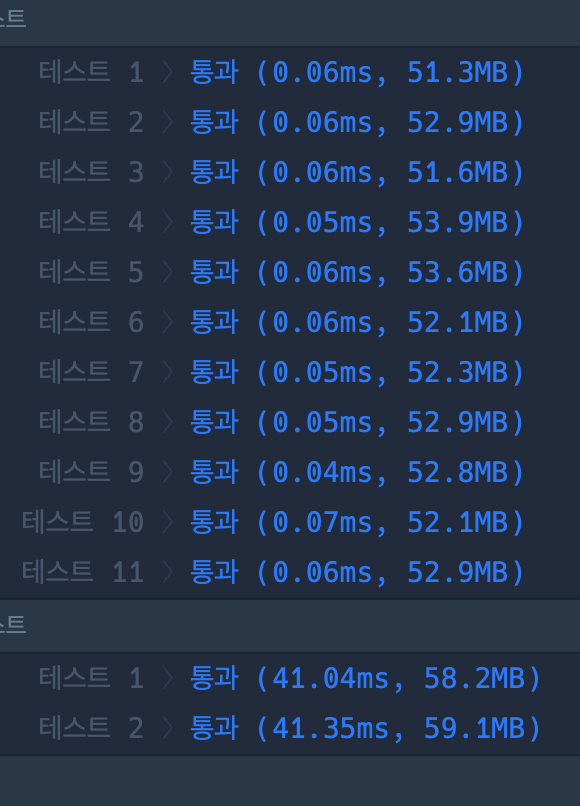
시간복잡도가 준 것은 아닌데 테스트를 통과해서 떨떠름하다. 다른 풀이를 보니 그냥 이중 포문을 사용해서 푼 경우도 있었다. 필자의 경우 indexOf를 했는데 그 분은 stratWith로 한 차이 밖에 없었다. 사용한 함수에 따라 달라질 수도 있다는건지,, 효율성을 평가하는 부분에서 약간 의아함이 들었다.